在 AI Agent 和数据驱动决策的时代,获取高质量、实时更新的结构化数据仍然是巨大痛点。手动爬虫易失效、传统工具难维护,而 TinyFish BigSet彻底改变了这一局面。它是一款**开源的多 Agent 系统**,只需用一句自然语言描述你想要的数据,就能自动从实时网页中抓取、验证、去重并生成结构化数据集,还能按计划自动刷新,保持数据永不过时。

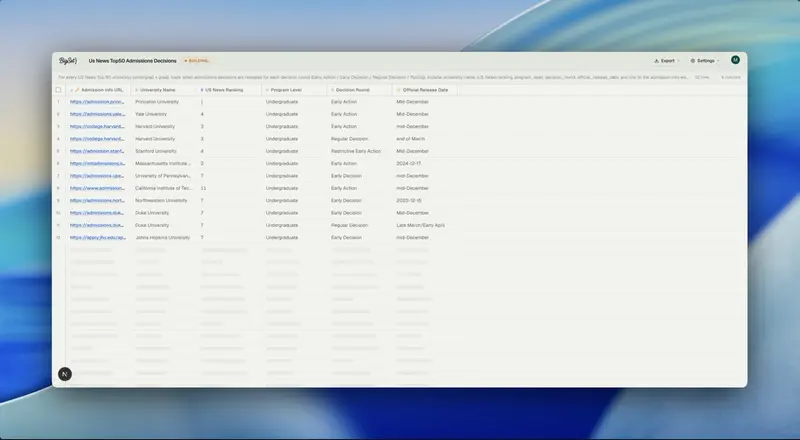
TinyFish Bigset 网站截图
BigSet 是什么?
BigSet 的核心理念是:“What if you had all the data in the world?” 你输入一句描述,例如:
“YC 公司中目前正在招聘工程师的列表,包括融资阶段、地点和开放职位数量。”
BigSet 会自动推断数据 Schema,派出自主 Agent 在全网搜索、验证信息,最终输出可浏览、可导出的结构化表格(CSV / XLSX)。更强大之处在于,你可以设置刷新频率(30 分钟、6 小时、每日、每周等),系统会自动重新运行 Agent,保持数据集最新。
它不是传统爬虫,而是多 Agent 协同系统,底层依赖 TinyFish 的网页搜索与抓取能力,结合 LLM 实现智能编排。目前项目处于实验阶段,但已展现出惊人潜力,适合需要实时市场情报、竞品分析、研究数据等场景。
核心特色亮点
- 自然语言驱动 无需写代码、无需指定 URL、无需设计 Selector。只需描述需求,AI 自动完成 Schema 推断、实体发现和数据填充。
- 自主多 Agent 工作流
- Orchestrator Agent 负责全局规划和搜索
- Sub-agents 并行调查每个实体,抓取页面并验证数据
- 内置去重、事实核查机制,确保数据质量
- 自动定时刷新 支持多种刷新周期,数据集永不过期。特别适合需要持续监控的价格、招聘、竞品动态等场景。
- 现代 Web UI + 导出功能 内置美观的前端界面,支持表格浏览、侧边栏展开详情、一键导出 CSV/XLSX。数据可直接用于 Excel、BI 工具或喂给其他 AI Agent。
- 高可扩展性与自托管 完全开源(AGPL-3.0),支持 Docker 一键部署。集成 Clerk 认证、Convex 数据库、Mastra 工作流等现代技术栈。
- 实验级强大能力 能处理跨站点、复杂结构的数据采集,如 GPU 价格、餐厅菜单、保险报价、研究论文等。只要信息在公开网页上存在,BigSet 就有机会构建出来。
如何部署与操作(详细步骤)
系统要求:安装 Docker 和 Make 命令。
1. 准备 API Keys(必须)
你需要三个服务的免费/付费密钥:
- TinyFish API Key:用于网页搜索和抓取
- OpenRouter API Key:用于 LLM 调用(推荐 Claude Sonnet + Qwen,,建议充值 5-10 美元)
- Clerk:用户认证(配置 Publishable Key、Secret Key 和 JWT Template)
2. 克隆项目并配置环境
Bash
git clone https://github.com/tinyfish-io/bigset.git
cd bigset
cp .env.example .env
在 .env 文件中填入上面获取的密钥。
3. 一键启动(推荐)
这个命令会自动:
- 安装依赖
- 启动 Postgres + 自托管 Convex 数据库
- 配置 Clerk 认证
- 启动前端、后端和 Mastra 工作流
- 生成必要的 Admin Key
启动完成后,访问以下地址:
- BigSet 主应用
- Convex 仪表盘
- Mastra Studio(工作流可视化)
4. 快速上手使用
- 打开 网站并登录(Clerk 认证)
- 点击 “Get Started”,输入你的数据集描述
- 系统自动生成 Schema 并开始构建(通常需 2-5 分钟)
- 构建完成后,在 UI 中浏览表格,或导出 CSV/XLSX
- 设置刷新频率,让数据集自动更新
可选:加载官方精选数据集演示:
Bash
make seed-public-datasets
5. 常用命令
- make dev:启动或恢复服务(最常用)
- make down:停止所有容器(数据保留)
- make clean:彻底清理数据并重置
- make convex-push:更新 Convex Schema
注意事项:
- 首次运行可能需要几分钟下载镜像和初始化数据库
- LLM 调用会产生少量费用(构建一个数据集几美元不等)
- 项目实验性较强,部分复杂主题效果可能不完美,欢迎提交 Issue
- 免费额度:每个账号每月 2500 行操作(系统精选数据集不受限)
为什么值得推荐?
BigSet 极大降低了获取实时结构化数据的门槛,让普通开发者也能轻松构建“活数据”。它特别适合:
- AI Agent 开发者(为 Agent 提供实时知识)
- 市场研究员、竞品分析师
- 数据爱好者和创业者
- 需要持续监控动态信息的团队
在 2026 年这个 Agent 爆发时代,BigSet 代表了一种新范式:数据即描述。无需成为爬虫专家,一句话就能拥有专属的实时数据集。